

Facebook annonçait en ce début Juin l’ouverture d’un centre R et D prochainement à Paris, le troisième du genre (après San Francisco et New York) dédié au machine Learning, science qui va puiser dans les techniques du Text Mining . Quoi de plus naturel sur le choix de la destination France, quand on sait que ce pôle de recherche est piloté par un français Yann Le Cun (et en partenariat étroit avec l’INRIA). Il est vrai que pour vendre de l’audience, il faut tirer du sens de toutes les images, textes et autres discours qui égrènent ce réseau social. Mais que renferme ce terme de Text Mining dans cet ensemble de techniques plus globalement appelé Text Analytics par les anglophones ? Débriefing sur quelques notions qui touchent de près ou de loin les métiers du webmarketing, et sans doute le Seo ! Définition, Usages et Outils vont tenter d’illustrer le sujet.
Définition de Text Mining
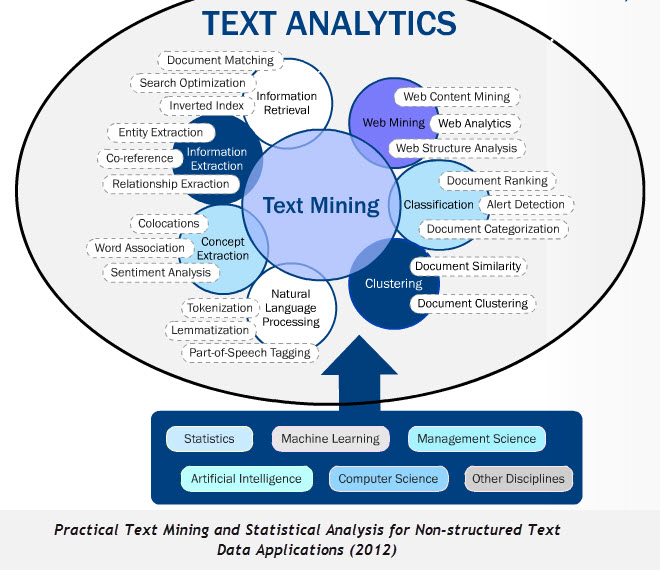
Je me garderai bien de jouer l’expert en la matière, vu sa complexité, mais vais partager les grandes lignes de cette discipline mise sur le devant de la scène depuis quelques années, avec l’apparition du concept de Big Data. Ce dernier apporte pour faire court, toute la puissance machine, pour traiter l’immense quantité de data via des Algorithmes, petites mains qui vont gérer la complexité. Au regard du schéma ci-dessous, le Text mining renferme 7 objets :
- Web mining : contenu, analytics,
- Classification : Ranking, catégorisation
- Clustering : Similarité, clusterisation
- Language Naturel : lemmatisation, étude du discours, tokenisation
- Extraction conceptuelle : association de mots, sentiment, colocation
- Extraction d’information : Extraction d’entités, co-référence, interrelation
- Récupération d’informations : Correspondance de documents, optimisation de la recherche, index inversé.
D’un point de vue Search Engine Optimisation, on peut dire que l’on est servi ! Toutes les techniques touchent de près ou de loin le métier du référenceur, et pour cause, sa matière première, son pétrole, ce sont les mots !
Univers du Text Mining
Plus généralement, on par le Text mining intéresse les disciplines de la statistique, de la gestion, de l’informatique, de l’intelligence artificielle, du machine learning, mais aussi a le vent en poupe en sciences sociales, linguistiques, journalisme, médias…
Usages du Text Mining
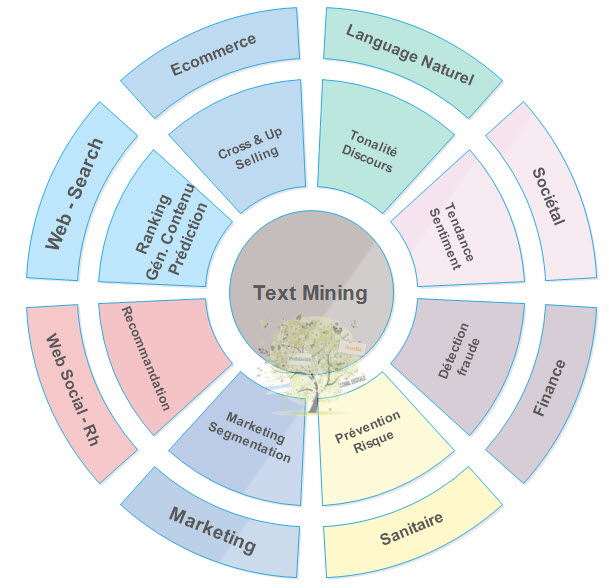
On pourrait résumer par ces quelques mots ce qu’englobe l’analyse textuelle : pouvoir, sans théorie pré-établie, par le recueil de l’information et sur la mesure seule, comprendre les mécanismes sous-jacents d’un ensemble de données, le sens global et extrapoler des tendances. Deux exemples :
Dans le domaine des moteurs de recherche, Google Now par le recueil et l’analyse des données centrées sur le profil utilisateur, anticipe sur ces comportements à venir, et pousse une information dite « prédictive ».
La recommandation algorithmique dans l’écosystème publicitaire du web social, est ce que le text mining peut produire de plus flagrant. Par étude des profils sociaux, par leur croisement, leur similarité, une extrapolation peut être déduite, pour enfin conseiller et pousser à un internaute une information pertinente dans son fil d’actualités.
Usages text mining
Outils : Algorithmes illustrés de text Mining
Comment traiter le sujet de la mécanique cachée du Text Mining ? Les formules des Algos, ouh là là, trop compliqué ! De toute façon, une formule scientifique avec fractions, opérandes et autres racines carrées, cela parle pas trop. J’ai donc cherché quelques outils en ligne gratuits pour « toucher du doigt » ces algorithmes de façon pratique, qui animent l’analyse des données dans nos vies de webmarketeurs.
Page Rank : Faire du lien pour du Ranking
C’est un des socles de la machinerie algorithmique de Google pour classer et positionner après avoir scrapé, analysé et indexé les différentes balises d’une page web. . ok tout le monde connaît :). On touche ici avec le PR à la popularité d’un site. Recevoir des liens vers et faire des liens vers, bref , le netlinking quoi !
Illustration : cette page web (voir lien fin article) matérialise via une matrice, un ensemble de site web, avec des cases à cocher qui constituent les liens que peuvent faire un site A vers un site B. Après validation de son netlinking, le PR de la page linkée augmente ou diminue selon la direction des liens.
PageRank demo
N’Gram : Densité, association et tendance
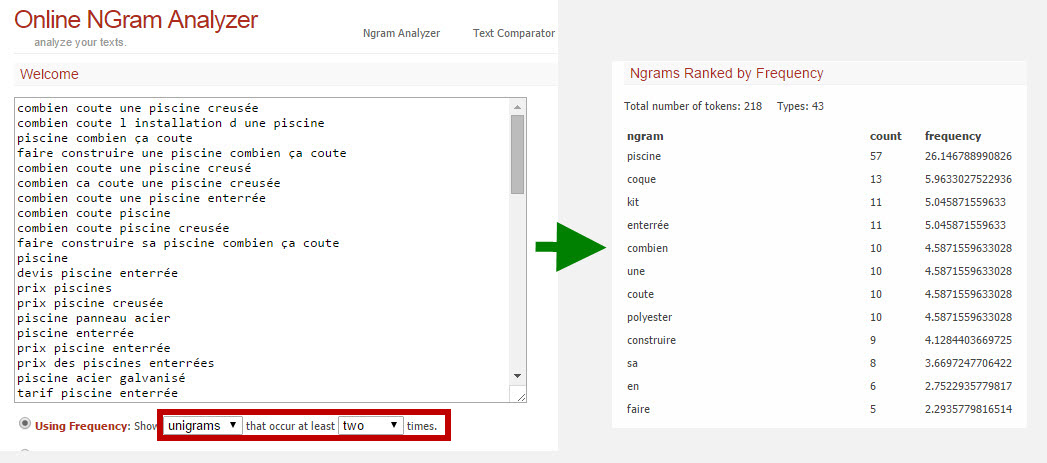
L’idée cette opération mathématique est de déceler à l’intérieur d’un texte ou corpus des associations de termes, on parle de relations de co-occurrence. En seo, c’est utile de savoir pourquoi Google trouve pertinent tel ou tel document, vis-à-vis d’une requête, afin d’établir son ranking,
N’Gram Analyser rend le concept concret. Vous avez une liste de mots clés sur laquelle vous souhaitez faire ressortir le terme dominant (par 1, 2 ou 3 termes associés), cela pourrait être aussi un texte (ou comparatif de textes). Copiez coller cette liste est établie avec un indice de fréquence. Cela peut être utilisé aussi en SEA pour segmenter un ensemble de mots clés.
Ngram analyzer
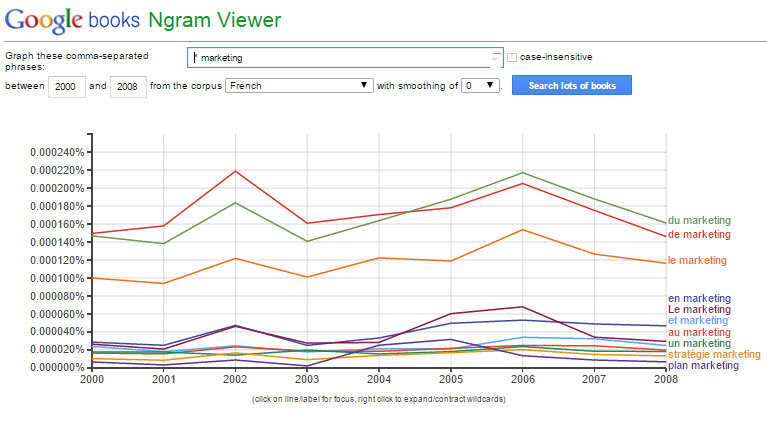
En seo, c’est utile aussi de sentir les tendances sur la fréquence et l’usage d’un mot clé. Cet outil proposé par Google « nGram viewer » permet connaître au travers tout un corpus de livres numérisés, les tendances d’apparition de termes. Il est possible aussi d’utiliser le « * » avant ou après le terme, pour connaître le type d’association . Pour /* marketing/, on s’aperçoit qu’entre 2000 et 2008 « stratégie marketing » se situe en bas de tableau quant à son usage…
Tendance d’ Association avec un mot clé
Tf/IDF : Du sens enfin !
Sert à comprendre ce dont parle un texte (fréquence d’un terme sur la fréquence du document) et de juger surtout de sa pertinence par rapport à un ensemble d’autres documents sur le même sujet. Les moteurs ne comprennent pas ce qu’ils lisent, mais par comparaison d’une variable (mot clé) dans un ensemble référent, la pertinence peut en être déduite.
Le site Wolfram propose une application desktop à télécharger et illustre tout un ensemble d’algos dont celui-ci et en fournit le code source. Ici, le texte anglais choisit parle d’un jugement judiciaire et la démonstration propose 4 fonctionnalités pour faire ressortir le poids de chacun des termes. Par simple activation sur la fréquence, et la mise en grisé des stops words, le sens global du texte est perçu sans avoir eu à le lire dans son ensemble.
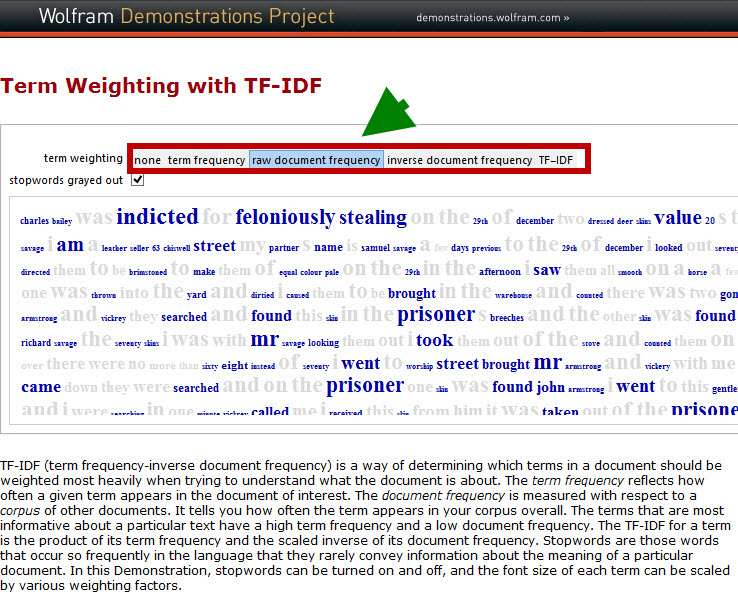
Tf IDF
Similarité : Pas de duplicate !
Comparer pour mieux régner. Vieil outil, mais qui fonctionne, pour mettre le doigt sur certaines analyses textuelles :
Proximité, matrice de comparaison. Pour l’exmple, les textes comparés définissent le terme de webmarketing issus de 2 sites web différents. Objectif : savoir s’ils se ressemblent ou pas selon un corpus basique de langue française. Lors de la création d’un contenu, se comparer vis-à-vis d’un contenu similaire au sein d’un corpus thématique peut aider dans le positionnement sur un moteur.
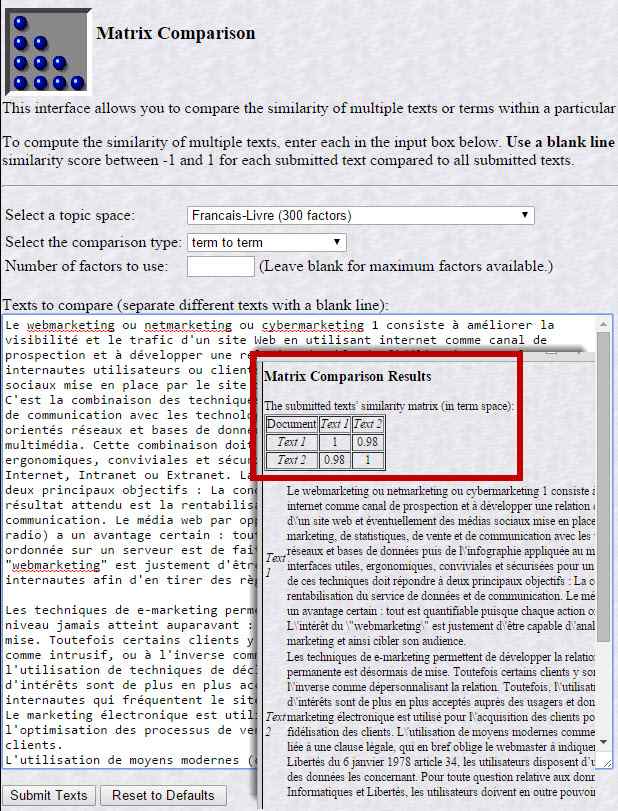
Matrice de Similarité
Site d’outils Analyse Textuelle
- PageRank : http://www.webworkshop.net/pagerank_calculator.php
- N’gramme :http://guidetodatamining.com/ngramAnalyzer/ & https://books.google.com/ngrams
- Tf/IDF : http://demonstrations.wolfram.com/
- LSA : http://lsa.colorado.edu/


