

Le web sémantique peut-il améliorer le seo ? Je ne sais pas si la question peut se poser ainsi mais je vais en tout cas essayer d’éclaircir ce sujet complexe ! Comment diffuser le sens réel de son contenu à des machines froides et imperturbables que sont les moteurs de recherche avec leur ingénierie algorithmique qui leur est attachée ? Replaçons la notion de l’internet sémantique dans son contexte, regardons pourquoi les moteurs s’y intéressent, et rentrons ensuite dans le concret de l’optimisation seo des contenus pour une page web.
Web sémantique : une annexe de l’intelligence artificielle ?
Deux récents articles publiés sur le site http://www.mkbergman.com et co-écrit par Mikael K. Bergman Ceo d’un société de conseil Structured Dynamics LLC et Fred Giasson , spécialisée dans les projets reliés à la sémantique web , abordent son histoire depuis 2005. Dans la deuxième partie de leur exposé, MKB avance l’idée selon laquelle le web sémantique n’arrive pas à rendre la « data » intégrable et encore moins interopérable par les organisations. Selon eux, une des voies d’optimisation de la circulation de la data seraient de positionner le web sémantique comme sous composante de l’intelligence artificielle. Il faut abolir les frontières technologiques et replacer le web sémantique dans un graphe global ou le concept de « big structure » permettrait l’interopérabilité des données. Dr Jiamai Han, chercheur en text mining, a pu même déclarer lors d’une conférence chez Yahoo ! que cette idée de big structure pouvait rendre ce big data plus intelligible en constituant un véritable réseau d’information ou ontologies (concepts) et structures du savoir se corrèleraient. Bon, je n’irai pas plus loin dans la synthèse de ces posts, je vous invite à les interpréter vous-même ! En attendant, un graphique vaut de grands discours, donc voici, recadré, la place du web sémantique au sein d’une représentation des différentes sphères de l’intelligence artificielle.
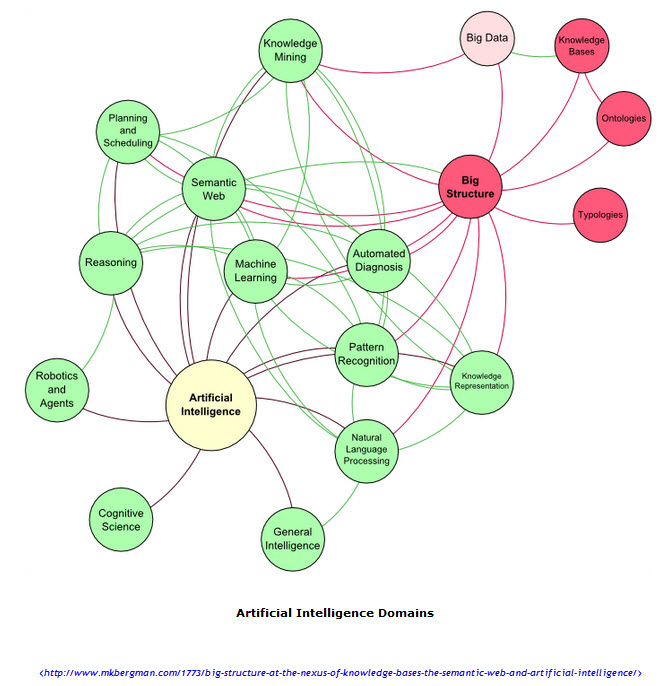
Place du Web Sémantique et notion de Big Structure
Web sémantique et Seo, vraiment d’actualité ?
Les intérêts des moteurs de recherche à donner du sens aux données
Améliorer les résultats de recherche grâce à une meilleure compréhension des corpus
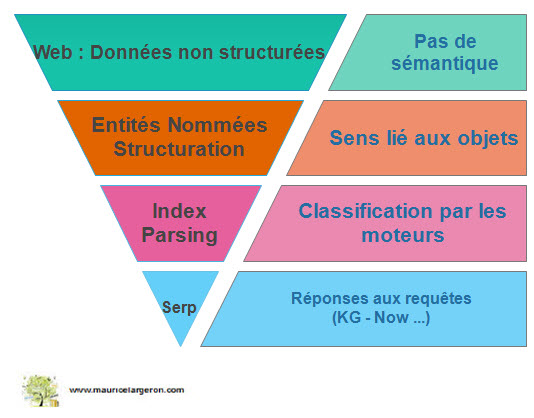
role-des-entitées-nommées
Cela semble évident mais cela va mieux en le disant ! Lever les ambiguïtés pour faire court, ce n’est pas anodin. Google ne comprend pas ce qu’il restitue, il s’appuie sur des algos. Nourris par des mots clés, des pages, des sites reliés entre eux par des liens hypertextuels. Les moteurs ne savent pas lire entre les lignes, seule la construction d’un référentiel parallèle (balisage standardisé) qui va décrire ce big data (composé de données non structurées et structurées) peut parvenir à le rendre plus intelligent et ainsi au final plus pertinent pour l’internaute. Un des moyens de rendre plus intelligible ce web, est la création d’entités nommées, qui sont des objets uniques pour identifier des éléments d’information. Microsoft donne une définition très explicite sur le sujet.
Definition entités nommées par Msn
On pourrait classifier trois types d’entités possédant chacun des propriétés et attributs.
- Les entités de recherche : une requête de recherche, un document, la période de la recherche, les liens sponsorisés déclenchés lors d’une demande, une ancre de lien, un domaine associé à la page web
- Les objets dépictants le réel : évènement, un lieu, une date, une personne, une recette…
- Les interrelations entre les entités avec un ciment constitué par le schéma : sujet – relation – Object (ex : Hollande – être – président)
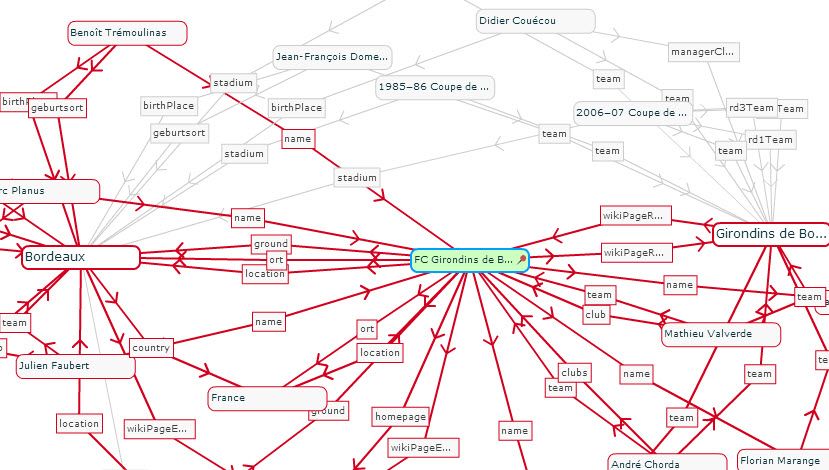
contexte-entre-entités-nommées
Répondre aux requêtes contextuellement
Les technologies multi-screen, mobiles et interactives par la voix et tactiles ont modifiés nos usages dans la recherche. Google s’est positionné sur ces changements matériels en mettant en avant des possibilités toujours plus puissantes de recherches qui s’en retrouvent simplifiées mais contextualisables. La connaissance de l’historique cross devices, le géolocalisation, le profilage des requêtes sont les principaux atouts pour répondre à la bonne personne au bon moment. L’application Google now est le fruit de cet ensemble d’avancées où se mixte des serp issus du web sémantique (horaires, météo, itinéraires), de la recherche personnalisée, du positionnement géographique.
Alléger la charge des Datacenters
Il est clair que « parser » des documents chartés, avec un référentiel commun issus d’énormes base de données comme Wikipédia, freeBase, Dmoz (fut un temps), banque de données universitaires simplifient le travail des centres de calculs. Leur classification et la taxonomie des corpus s’en trouvent facilité et donc les moteurs de recherche ont tout à y gagner dans l’élaboration de leur corpus.
Contenu « sémantisé » pour un site web
Attention, toute la recherche n’est pas concernée par la montée du web sémantique, mais la tendance va vers une progression sans cesse croissante dans les serp de Google. Les pages individuellement, en dehors du graphe de Google peuvent être optimisées afin d’être mieux interprétées.
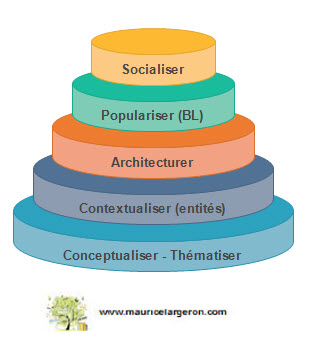
Feuille de route pour contenu web
Comment relier concrètement ce web sémantique à une problématique journalière de production de contenus ? Comme toujours il faut partir de ces premiers mots clés métier et ensuite rechercher à les contextualiser et les conceptualiser par la recherche d’entités nommées. Ci dessous, un corpus issus de plusieurs bases de données permettent de souligner les relations entre 2 entités. Cela peut enrichir la réflexions sur les contenus à produire ainsi qu’à souligner leur environnement.
Recherche de contexte sur visualdataweb.org
Optimisation sémantique On Site
Une fois ébauché la thématique que renferme ces mots clés, il faudra l’architecturer (organigramme) afin de donner du poids aux requêtes visées selon l’environnement concurrentiel. On parle ici de topic modeling, d’architecture sémantique (microsite dans le site) de cocon sémantique, terme vulgarisé par Laurent Bourrelly avec un grand merci pour son boulot pédagogique ! Faut-il créer une arborescence de 5, 10, 35 pages pour valoriser une page « catégorie » ? Seul un audit du marché de la requête permettra de déployer une stratégie de contenus fiable. Cet ensemble de page devra être articulé selon une logique sémantique globale.
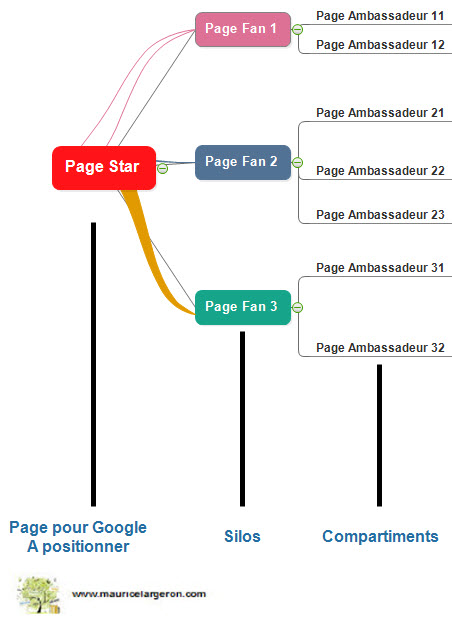
Architecture sémantique pour requete web
Préparer les pages au scan du crawler (onpage)
L’analyse textuelle de Google utilise dans ses algorithmes des techniques d’analyse textuelles :
- Latent semantic Indexing : relation entre un ensemble de documents et les termes qu’ils contiennent (conceptualisation)
- Lemmatisation : Recherche selon une famille de mots ayant la même racine.
- Occurences – co-occurrence (contiguîté de termes) et N-gramme : calcul de la quantité et la fréquence d’une seule ou paire d’unité présents dans un corpus . Le n-gramme assiste dans l’analyse de la séquence de 2 ou plusieurs mots clés.
- Tf-idf : Attribution d’un score sur la l’importance d’un terme dans un document (pertinence d’un mot clé)
De ce fait la page devra être rédigée dans une logique moteur sans oublier le lecteur. Un exercice d’équilibriste ! Il sera donc conseiller de procéder à :
- Une segmentation en blocs de contenus par un balisage html soigné
- un usage de mots clés vedettes, synonymes précis
- la spatialisation des termes dans l’article
- Un balisage sémantique d’objets spécifiques : noms, recettes, personnes, boutons (schéma, entités nommées (voir illustration avec la syntaxe “sameAs”, openGraph)
- Un netlinking interne entre les pages d’une même thématique (siloisation, archi.)
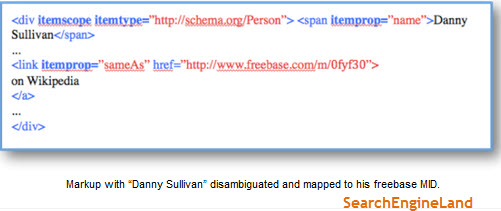
Désambiguité des termes dans un contenu
Populariser ses objets
Donc si l’on vise directement des serp du Knowledge graph par exemple, rien n’empêche d’aller créer du contenu sur wikipédia, de s’enregister sur FreeBase …ou sinon, compter encore sur les bons vieux liens entrants !
Webographie sur sémantique web
- Big Structure : http://www.mkbergman.com/1771/a-decade-in-the-trenches-of-the-semantic-web/
- Topic Modelling : http://moz.com/blog/topic-modeling-semantic-connectivity-whiteboard-friday
- Sept optimization onpage : http://moz.com/blog/7-advanced-seo-concepts
- Entités nommées : http://www.seobythesea.com/2013/08/relationships-search-entities/
- FreeBase : https://www.freebase.com/


