

Le printemps approche, et la nature, s’il y a encore des saisons, va réitérer son processus de floraison sans aucune duplication. Bon, d’accord, la transition sur le sujet qui nous intéresse cette semaine, à savoir, le contenu dupliqué pour un site web, est un peu facile mais bon, les rayons de soleil font du bien. Sans parler de spam, de black hat attitude, les contenus sur le web ont une tendance naturelle à l’inverse des marguerites de printemps, à se répliquer à l’identique et affecter un tant soit peu, les efforts d’optimisation pour les moteurs de recherche (seo). Quelles sont les causes de duplicate content ? Les remèdes ? Mais revenons sur son origine..
Historique du phénomène
La duplication de contenu ne date pas d’hier, dans la vraie vie, quand elle est intentionnelle on peut parler de plagiat, sur le web, on vulgarise cela comme une des techniques qui visent à copier des textes puis à les transformer afin de créer des contenus d’une manière artificiel (à l’aide de techniques machines de génération de contenus dont celle du spinning par exemple) . Dès les premières instants du web, l’information se propage et par là même se duplique, via des process d’architectures de sites par exemple, sans même sans réelle intention de nuire, sinon qu’a soi même (éditeur) !
Google, face à cette croissance des données dupliquées, se doit de faire le tri et déterminer le bon grain de l’ivraie. Dès 2005, la mise à jour de l’algorithme « Bourbon » porte sur le duplicate content et notamment intersite (domaine différents) mais aussi intrasite (au sein d’un même domaine).
En 2006, le blog anglais fait une mise au point « publique » de ce qu’il entend comme étant la duplication de contenus (voir ici)
En 2008, google sort quelques chiffres et cite qu’il n’indexait que 1000 milliards sur les 3000 présentes, parmi, certainement des contenus en double, non ?
Récemment, la part des documents recopiés sur le net avoisinerait les 30% (j’ai perdu la source M) serait vraisemblablement celui qui représente
Origines et remèdes à la duplication de contenu
L’url est la cause de tous les mots !
Un contenu unique doit avoir pour destination une url et pas plus ! Si, plusieurs url aboutissent à un même texte pour l’exemple, alors il y aura duplication, c’est purement technique, mais c’est comme cela. On le verra plus loin, des dérivés existent aussi, liés au balisage html des pages.

1 url = 1 contenu
Le duplicate content lié au site
La faute aux serveurs web
Certains documents suite à des essais effectués par des développeurs sur des serveurs logés sur des sous domaines peuvent être indexés par les moteurs. Le mieux est d’empêcher par une directive dans le fichier robot.txt l’accès à cette sous partie de test du site, ou par une directive dans le Template par la balise meta :noindex
Phénomène de Dust
Le script qui génère le site , produit des urls différentes qui , si elles ne sont pas corrigées, amènent toujours vers la page d’accueil. Les cas sont diverses, mais si les redirections ne sont pas automatiques, du domaine Tld monsite.com vers des sous domaines comme le « www » , ou alors, s’il existe plusieurs noms de domaine pour un même site (.fr/.com) , on se retrouve en duplication !
Une bonne redirection 301 résout le problème.
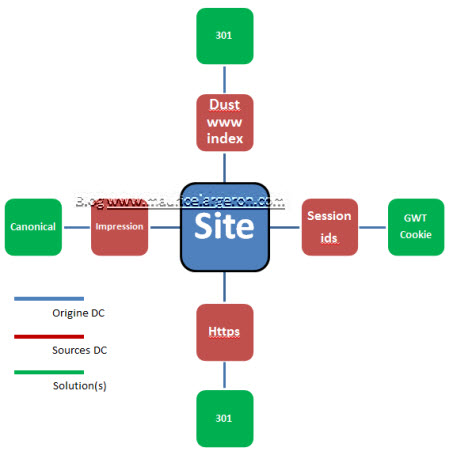
4 sources de duplication site
Les paramètres « ids » l’url
le « / » oublié à la fin des urls, à l’origine, les moteurs ne savaient pas gérer ce soucis, maintenant oui, ouf !
Les identifiants de session, qui servent pendant la visite à accorder aux visiteurs une identification unique lui permettant de gérer des fonctionnalités comme le panier, son authentification sont stockées dans l’url et viennent à être indexées. Le mieux est de gérer cela dans un cookie ou alors dans un balisage canonique.
Https version
Les pages de panier et de paiement nécessitent une sécurisation, mais parfois peuvent se calquer sur des pages produits et produisent des pages doublons. Normalement, le site en lui-même gère cette problématique, en cas inverse, il conviendra de rediriger les versions similaires https:// vers celles http:// en 301.
Les paramètres fonctionnels comme l’impression ..
Une version imprimée d’une page, à la fin de l’url, un paramètre tel que : /reunion-parents-professeurs&impr=1 peuvent se rajouter, il conviendra d’utiliser le tagage canonique sur la page principale.
DC lié aux contenus
Un balisage tout venant
Ici le balisage des titres des pages (meta <title> ou <description>) est redondant, dommage pour l’indexation de google qui préfèrera à contenu identique, un titre et une description uniques pour chaque page. l’outil google webmaster tool indique les erreurs , il suffit de les corriger par une re-écriture.
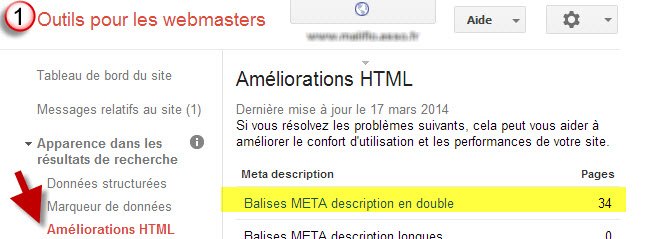
Doublon des balises Meta
De faire des filtres et tris divers sur du contenu
pieces-informatique/carte-memoire/c4700/+fb-C000001009,C000001080+fv41-2825.html , le mieux sera de bloquer les paramètres dans gwt
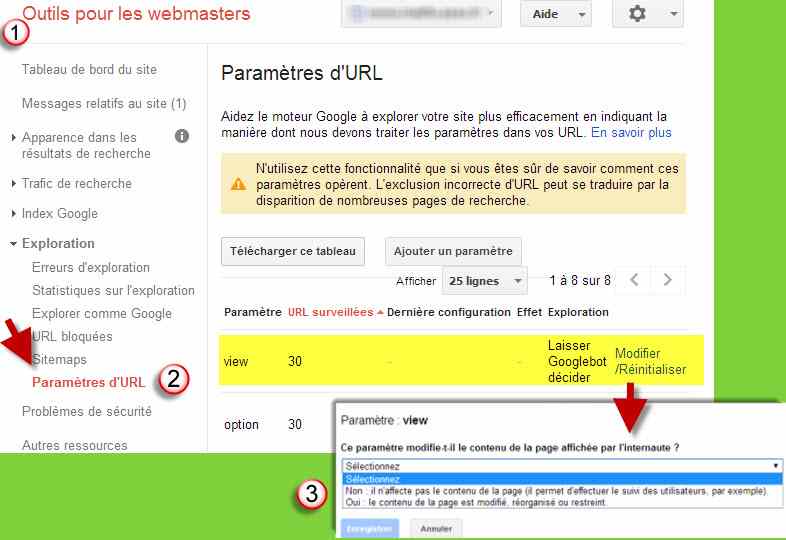
Correction des paramètres dans l’url
Pagination et commentaires (ugc)
Lorsqu’un article est découpé en plusieurs parties distinctes avec des urls qui ressemblent à
- www.monsite.fr/article-partie-1.html
- www.monsite.fr/article-partie-2.html
- www.monsite.fr/article-partie-3.html
- www.monsite.fr/commentaire-page-1 etc /comment-page-2/
A priori Google reconnait désormais le canevas général, ou alors , il suffit de rajouter un balisage spécifique dédié <link rel= »prev » href= »http://www.monsite.fr/article-partie-2.html »> . Enfin, autre solution, créer une page unique qui rassemble le contenu des 3 autres et baliser une Meta Noindex,Follow sur les 2 autres ou alors d’y mettre une balise canonique qui renvoie sur la page principale (voir documentation Google bien faîte)
Plusieurs versions (langues, pays)
Si une url est valide pour plusieurs variantes selon les pays comme la France, canada, Belgique, il conviendra de baliser chaque page avec cet ajout : rel= »alternate » hreflang= »x » , le « x » renvoyant vers la norme qui représente le pays (fr-ch par exemple pour la suisse).
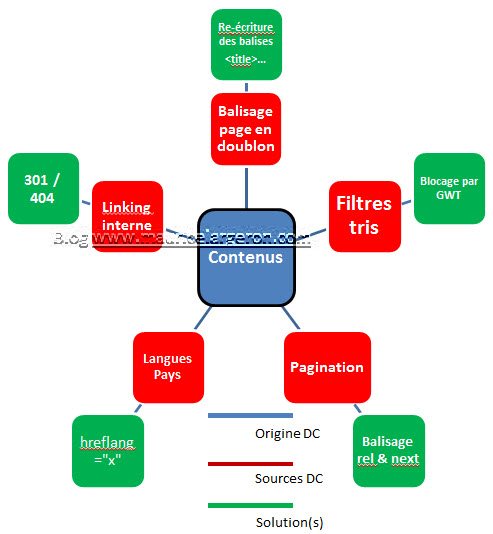
DC lié plus aux contenus meme
Autre exemple : http://www.example.com/ avec http://en-gb.monsite.fr/page.html et http://en-us.monsite.fr/page.html , il conviendra de baliser avec rel= »alternate » hreflang= »x » au niveau de chacune des pages qui redirigera le navigateur vers le bon répertoire ou sous domaine du site traduit.
Le linking interne défectueux
Avec des pages un peu oubliées sans balisage canonique faisant l’objet de liens entrants.
Des doublons liés à l’environnement du site
Syndication : si le site propose un flux rss, l’idéal est de proposé un court extrait qui ne sera pas considéré comme une ressources dupliquée par les moteurs.
Aspirateurs de site/scrapers : Normalement, Google s’est identifier l’original à la copie de mieux en mieux entre domaines, alors…Ceci dit, rien n’empêche d’utiliser des outils du style copyscape ou autres pour aller voir si son contenu n’a pas fait des petits çà et là.
Liens externes comme les d’affilliation
Du genre : http://www.monsite.fr/click-85973256-4569873 , il faudra user du balisage canonique bien sûr, ou alors de bloquer les paramètres de l’url, mais le mieux est d’utiliser le « # » hash tag à la place.
Quelques remèdes anti-duplication supplémentaires
- Retirer l’url de l’index de Google dans Google webmaster tool
- Faire un lien retour vers le contenu original si pas de moyen de le faire via le code source (301/Meta/canonique..)
Des ressources en liens sur la toile
Google sur pagination et langues
- contenu dupliqué : https://support.google.com/webmasters/answer/66359?hl=fr
- Pagination : https://support.google.com/webmasters/answer/1663744?hl=fr
Un article intéressant de Thomas Gilbertie


